MuleSoft-Integration-Architect-I合格率 & MuleSoft-Integration-Architect-Iトレーリングサンプル
Wiki Article
ちなみに、Xhs1991 MuleSoft-Integration-Architect-Iの一部をクラウドストレージからダウンロードできます:https://drive.google.com/open?id=1j5DkZW72Hn4dCwNkIglDfCVW2aaccdNS
Xhs1991製品を購入する前にMuleSoft-Integration-Architect-I学習ツールの無料ダウンロードと試用を提供し、製品のデモを提供して、クライアントに製品を完全に知らせます。 WebサイトのMuleSoft-Integration-Architect-Iテストトレントのページにアクセスすると、MuleSoft-Integration-Architect-Iガイドトレントの特性とメリットを知ることができます。 Webサイトの製品のページでは、詳細と保証、連絡方法、MuleSoft-Integration-Architect-Iテストトレントでのクライアントの評価、およびMuleSoft-Integration-Architect-I試験問題に関するその他の情報を見つけることができます。とても便利です。
Salesforce MuleSoft-Integration-Architect-I 認定試験の出題範囲:
| トピック | 出題範囲 |
|---|---|
| トピック 1 |
|
| トピック 2 |
|
| トピック 3 |
|
| トピック 4 |
|
| トピック 5 |
|
| トピック 6 |
|
| トピック 7 |
|
>> MuleSoft-Integration-Architect-I合格率 <<
実際的なMuleSoft-Integration-Architect-I合格率 & 合格スムーズMuleSoft-Integration-Architect-Iトレーリングサンプル | ハイパスレートのMuleSoft-Integration-Architect-I資格トレーニング
MuleSoft-Integration-Architect-I練習資料は、MuleSoft-Integration-Architect-I試験に簡単に合格するのに役立ちます。 MuleSoft-Integration-Architect-Iの学習資料に雇われたXhs1991業界の専門家は、理解しにくいすべての専門用語を例、図などで説明しています。MuleSoft-Integration-Architect-Iの実際のテストで使用されるすべての言語は非常にシンプルで理解しやすいものでした。 MuleSoft-Integration-Architect-I学習教材を使用すると、プロの本の内容を理解していないことを心配する必要はありません。 また、家庭教師のクラスに行くために高価な授業料を費やす必要はありません。Salesforce Certified MuleSoft Integration Architect IのMuleSoft-Integration-Architect-Iテストエンジンは、研究のすべての問題を解決するのに役立ちます。
Salesforce Certified MuleSoft Integration Architect I 認定 MuleSoft-Integration-Architect-I 試験問題 (Q65-Q70):
質問 # 65
An organization uses a set of customer-hosted Mule runtimes that are managed using the Mulesoft-hosted control plane. What is a condition that can be alerted on from Anypoint Runtime Manager without any custom components or custom coding?
- A. When the Mute runtime license installed on a Mule runtime is about to expire
- B. When a Mule runtime's customer-hosted server is about to run out of disk space
- C. When an SSL certificate used by one of the deployed Mule applications is about to expire
- D. When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods
正解:D
解説:
Correct answer is When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods Using Anypoint Monitoring, you can configure two different types of alerts: Basic alerts for servers and Mule apps Limit per organization: Up to 50 basic alerts for users who do not have a Titanium subscription to Anypoint Platform You can set up basic alerts to trigger email notifications when a metric you are measuring passes a specified threshold. You can create basic alerts for the following metrics for servers or Mule apps: For on-premises servers and CloudHub apps: * CPU utilization * Memory utilization * Thread count Advanced alerts for graphs in custom dashboards in Anypoint Monitoring. You must have a Titanium subscription to use this feature. Limit per organization: Up to 20 advanced alerts
質問 # 66
An organization plans to migrate all its Mule applications to Runtime Fabric (RTF). Currently, all Mule applications have been deployed to CloudHub using automated CI/CD scripts.
What steps should be taken to properly migrate the applications from CloudHub to RTF, while keeping the same automated CI/CD deployment strategy?
- A. A runtimefFabricDeployment profile should be added to Mule configuration properties YAML files in all the Mule applications.
CI/CD scripts must be modified to use the new configuration properties. - B. runtimefabricDeployment profile should be added to the pom.xml file in all the Mule applications. CI/CD scripts must be modified to use the new RTF profile.
- C. runtimeFabric command-line parameter should be added to the CI/CD deployment scripts.
- D. A runtimefabric dependency should be added as a mule-plugin to the pom.xml file in all the Mule applications.
- E. The pom.xml and Mule configuration YAML files can remain unchanged in each Mule application.
A --runtimeFabric command-line parameter should be added to the CI/CD deployment scripts
正解:D
質問 # 67
Refer to the exhibit.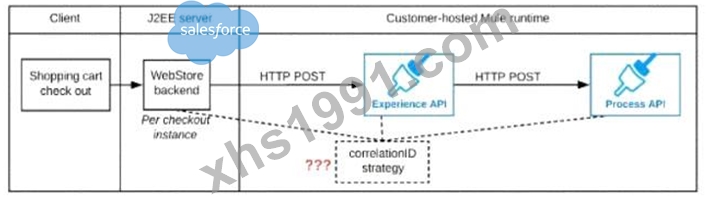
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A)
The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID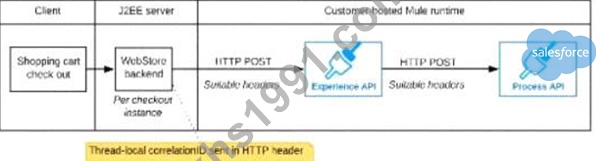
B)
The web store backend generates a new correlation ID value at the start of checkout and sets it on the X- CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID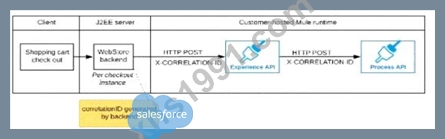
C)
The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header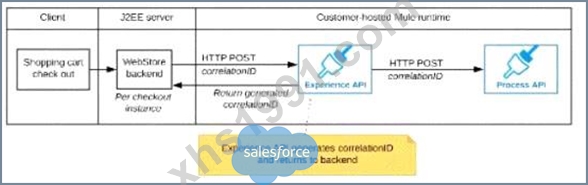
D)
The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers
- A. Option D
- B. Option C
- C. Option B
- D. Option A
正解:C
解説:
Correct answer is "The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATION-ID HTTP request header in each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID" Explanation : By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
Mulesoft Reference: https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-Flows-with- HTTP-Endpoint-in-Mule-4 Graphical user interface, application, Word Description automatically generated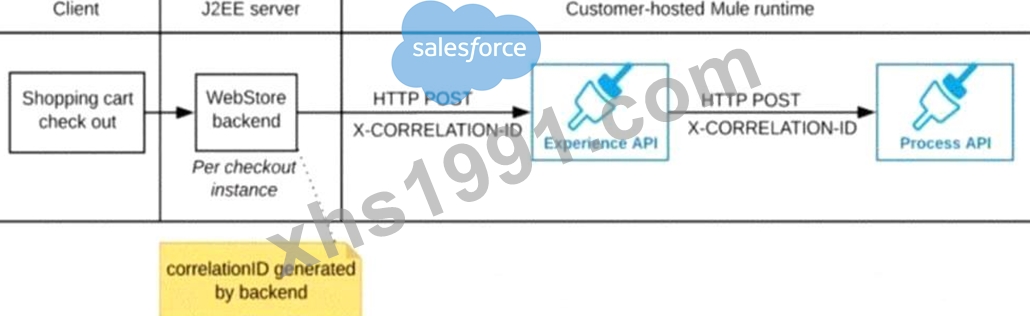
質問 # 68
A mule application designed to fulfil two requirements
a) Processing files are synchronously from an FTPS server to a back-end database using VM intermediary queues for load balancing VM events b) Processing a medium rate of records from a source to a target system using batch job scope Considering the processing reliability requirements for FTPS files, how should VM queues be configured for processing files as well as for the batch job scope if the application is deployed to Cloudhub workers?
- A. Use VM connector persistent queues for FTPS file processing Disable VM queue for the batch job scope
- B. Use Cloud hub persistent VM queues for FTPS file processingDisable VM queue for the batch job scope
- C. Use Cloud hub persistent VM queue for FTPS file processingThere is no need to configure VM queues for the batch jobs scope as it uses by default the worker's JVM memory for VM queueing
- D. Use Cloud hub persistent queues for FTPS files processingThere is no need to configure VM queues for the batch jobs scope as it uses by default the worker's disc for VM queueing
正解:D
解説:
When processing files synchronously from an FTPS server to a back-end database using VM intermediary queues for load balancing VM events on CloudHub, reliability is critical. CloudHub persistent queues should be used for FTPS file processing to ensure that no data is lost in case of worker failure or restarts. These queues provide durability and reliability since they store messages persistently.
For the batch job scope, it is not necessary to configure additional VM queues. By default, batch jobs on CloudHub use the worker's disk for VM queueing, which is reliable for handling medium-rate records processing from a source to a target system. This approach ensures that both FTPS file processing and batch job processing meet reliability requirements without additional configuration for batch job scope.
References
* MuleSoft Documentation on CloudHub and VM Queues
* Anypoint Platform Best Practices
質問 # 69
A company is designing a mule application to consume batch data from a partner's ftps server The data files have been compressed and then digitally signed using PGP.
What inputs are required for the application to securely consumed these files?
- A. ATLS context Key Store requiring the private key and certificate for the company PGP public key of partner PGP private key for the company
- B. ATLS context first store containing a public certificate for partner ftps server and the PGP public key of the partner TLS contact Key Store containing the FTP credentials
- C. TLS context trust or containing a public certificate for the ftps server The FTP username and password The PGP public key of the partner
- D. The PGP public key of the partner
The PGP private key for the company
The FTP username and password
正解:D
解説:
To securely consume compressed and digitally signed files from a partner's FTPS server, the following inputs are required:
* PGP Public Key of the Partner:
* Purpose: Used to verify the digital signature of the files received from the partner. This ensures that the files were indeed sent by the partner and have not been tampered with.
* Implementation: Import the partner's PGP public key into the Mule application.
* PGP Private Key for the Company:
* Purpose: Used to decrypt the files that were encrypted by the partner using the company's public key. This ensures that only the intended recipient (the company) can access the contents of the files.
* Implementation: Configure the Mule application to use the company's PGP private key for decryption.
* FTP Username and Password:
* Purpose: Used to authenticate and establish a connection to the partner's FTPS server. The credentials ensure that only authorized users can access the server.
* Implementation: Provide the FTP credentials in the Mule application's FTPS connector configuration.
By using these inputs, the Mule application can securely connect to the FTPS server, verify the integrity and authenticity of the files using PGP, and decrypt the contents for further processing.
References
* MuleSoft FTPS Connector
* MuleSoft PGP Module
質問 # 70
......
何事でもはじめが一番難しいです。MuleSoft-Integration-Architect-I試験への復習に悩んでいますか?弊社の提供するソフトを買うのはあなたの必要の第一歩です。弊社の保証がある問題集を入手して、試験に合格するチャンスが大きくなります。疑問がありましたら、Xhs1991で無料のデモをダウンロードしてやってみることができます。
MuleSoft-Integration-Architect-Iトレーリングサンプル: https://www.xhs1991.com/MuleSoft-Integration-Architect-I.html
- Salesforce MuleSoft-Integration-Architect-I認定試験に関連する最高な過去問問題集 ✍ 今すぐ▶ www.xhs1991.com ◀を開き、( MuleSoft-Integration-Architect-I )を検索して無料でダウンロードしてくださいMuleSoft-Integration-Architect-I試験内容
- MuleSoft-Integration-Architect-I認定デベロッパー ???? MuleSoft-Integration-Architect-I模擬資料 ???? MuleSoft-Integration-Architect-I日本語復習赤本 ???? 《 www.goshiken.com 》から簡単に✔ MuleSoft-Integration-Architect-I ️✔️を無料でダウンロードできますMuleSoft-Integration-Architect-I試験概要
- MuleSoft-Integration-Architect-Iの無料サンプル、MuleSoft-Integration-Architect-I参考書パス ???? ➤ jp.fast2test.com ⮘を開き、➤ MuleSoft-Integration-Architect-I ⮘を入力して、無料でダウンロードしてくださいMuleSoft-Integration-Architect-I赤本合格率
- 素晴らしいMuleSoft-Integration-Architect-I合格率 - 合格スムーズMuleSoft-Integration-Architect-Iトレーリングサンプル | 実用的なMuleSoft-Integration-Architect-I資格トレーニング ???? ▛ www.goshiken.com ▟には無料の⮆ MuleSoft-Integration-Architect-I ⮄問題集がありますMuleSoft-Integration-Architect-I日本語復習赤本
- MuleSoft-Integration-Architect-Iの無料サンプル、MuleSoft-Integration-Architect-I参考書パス ???? 《 www.jpexam.com 》は、➥ MuleSoft-Integration-Architect-I ????を無料でダウンロードするのに最適なサイトですMuleSoft-Integration-Architect-I学習指導
- MuleSoft-Integration-Architect-I合格記 ???? MuleSoft-Integration-Architect-I試験内容 ???? MuleSoft-Integration-Architect-I模擬資料 ???? { www.goshiken.com }を入力して✔ MuleSoft-Integration-Architect-I ️✔️を検索し、無料でダウンロードしてくださいMuleSoft-Integration-Architect-I日本語版サンプル
- 100%合格率の-権威のあるMuleSoft-Integration-Architect-I合格率試験-試験の準備方法MuleSoft-Integration-Architect-Iトレーリングサンプル ???? 【 www.passtest.jp 】サイトで{ MuleSoft-Integration-Architect-I }の最新問題が使えるMuleSoft-Integration-Architect-I資格トレーリング
- 素晴らしいMuleSoft-Integration-Architect-I合格率 - 合格スムーズMuleSoft-Integration-Architect-Iトレーリングサンプル | 実用的なMuleSoft-Integration-Architect-I資格トレーニング ???? ( www.goshiken.com )に移動し、【 MuleSoft-Integration-Architect-I 】を検索して、無料でダウンロード可能な試験資料を探しますMuleSoft-Integration-Architect-I復習内容
- MuleSoft-Integration-Architect-I合格内容 ???? MuleSoft-Integration-Architect-I学習指導 ???? MuleSoft-Integration-Architect-I模擬資料 ???? Open Webサイト☀ www.goshiken.com ️☀️検索➥ MuleSoft-Integration-Architect-I ????無料ダウンロードMuleSoft-Integration-Architect-I日本語版参考書
- MuleSoft-Integration-Architect-I実際試験 ✳ MuleSoft-Integration-Architect-I試験概要 ???? MuleSoft-Integration-Architect-I前提条件 ???? ウェブサイト{ www.goshiken.com }を開き、➡ MuleSoft-Integration-Architect-I ️⬅️を検索して無料でダウンロードしてくださいMuleSoft-Integration-Architect-I復習内容
- 認定する-検証するMuleSoft-Integration-Architect-I合格率試験-試験の準備方法MuleSoft-Integration-Architect-Iトレーリングサンプル ???? ▛ www.xhs1991.com ▟の無料ダウンロード➥ MuleSoft-Integration-Architect-I ????ページが開きますMuleSoft-Integration-Architect-I受験内容
- adrianacsyg616673.p2blogs.com, haarispheb935342.blogrenanda.com, www.stes.tyc.edu.tw, zakariatyuy148667.theisblog.com, nelsonkjnd545524.bcbloggers.com, prestoncuhi860606.qodsblog.com, mirrorbookmarks.com, marvinyics502425.westexwiki.com, www.stes.tyc.edu.tw, hindibookmark.com, Disposable vapes
無料でクラウドストレージから最新のXhs1991 MuleSoft-Integration-Architect-I PDFダンプをダウンロードする:https://drive.google.com/open?id=1j5DkZW72Hn4dCwNkIglDfCVW2aaccdNS
Report this wiki page